


Entering the Black Box of GPT-3
Dissecting Bias in Generative AIs



By now you may have tried your hand at testing out GPT-3, the third version of the Generative Pre-Trained Transformer developed by OpenAI. GPT-3 has remarkable capabilities in solving complex tasks and producing high quality text and visual content that rival much of that created by humans. Popular applications of generative AI include copywriting tool Jasper, Github’s Copilot code generation app, and DALL-E, OpenAI’s 12-billion parameter image generator.
DALL-E alone has enabled an explosion of creativity, allowing anyone to instantly create unique and professional-grade images of almost anything they can dream up. However, if you spend enough time giving the AI artist prompts, you’ll start to notice that DALL-E has certain tendencies that reflect existing social norms, or rather, it has a social bias.
Stylistically, AI image generators skews towards outputting images with Western art styles. It is possible to explicitly prompt DALL-E to generate art that emulates other cultural styles or specific artists, like using modifier “Ukiyo-e” which will generate art in the style of Japanese woodblock prints and paintings, but non-Western cultural styles are rarely the default or notably present.
Image-focused generative AI’s also tend to have a strong identity bias. Not specifying a race or ethnicity will frequently render caucasian subjects. It also reinforces gender norms, consistently representing professionals as the gender most stereotypically associated with that profession.

There are also many generative AIs focused on text-writing. OpenAI has its own wildly popular and recently released text-based chatbot, ChatGPT. Popular notes and organization app, Notion, recently released Notion AI, which helps you generate blog posts, press releases, job description or any text really from a simple prompt.
Just yesterday Mem, an AI-powered workspace, announced the launch of their knowledge-aware AI writer: Mem X Smart Write & Edit.

While bias may be harder to quickly spot in a sea of written text than in a grid of images, the presence of bias is in many ways even more stark in written content. In a 2021 study Stanford and McMaster researchers compared the most strongly analogized words of different religions in GPT-3. Some of the strongest associations were unsurprising like “Christian” and “faithfulness” at 5%, “Buddhist” and “enlightened” at 13%, and “Atheist” and “godless” at 13%. However, the most often analogized word with “Muslim” was “terrorist” at an alarming 23%.

The researchers then prompted GPT-3 with the open-ended line “Two Muslims walked into a…” and 66 of 100 times it produced phrases and words with a high association with violence.

The most recent advances in text-generation rely on using a predictor for the most likely word or phrase to follow the text accumulated thus far, leaning on stringing together phrases with higher co-occurrence. This renders heavy weighting on biased associations extremely insidious.
The characteristics and behaviors of GPT-3 are shaped by the input data that it's trained on, which is taken from all over the internet — Wikipedia, books, articles, Common Crawl data, etc. The output is not a copy, but an emulation of the information, style and other attributes of the input. Unsurprisingly, it mirrors the human biases and unequal representation that runs rampant in the contents of the internet. As put by Amelia Winger-Bearskin, professor of AI and the Arts at the University of Florida’s Digital Worlds Institute, “All AI is only backward-looking. They can only look at the past, and then they can make a prediction of the future.”
This is not a new problem for the field of AI. A 2018 study by Dr. Joy Buolamwini demonstrated racial and gender discrimination in machine learning algorithms for facial analysis where it showed darker-skinned females being misclassified at an error rate of up to 34.7% meanwhile lighter-skinned males had a maximum error rate of 0.8%. The difference however, is that GPT-3 and other LLMs (large language models) are far more poised to legitimately undermine and replace the core daily tasks we perform today than any previous machine learning models. There is a visceral improvement that we have already observed between the applications of recent developments in generative AI versus previous machine learning models. Modern generative AIs have an almost magical ability to turn any human input (text prompt) into completion of a sophisticated task (e.g. writing a full coherent essay on roman history, generate usable figma designs in a matter of seconds, create 3D objects that can be immediately usable in a virtual game, and much more). The underlying technological leap from previous machine learning models to current LLMs is staggering.
Machine learning has historically relied on developers hand-tuning algorithms with specific datasets and for specific tasks, which was expensive and had a high bar for entry. Recent breakthroughs with foundation models (including DALL-E, GPT-3 and more), however, have obviated this work for a large class of machine learning tasks. Instead of collecting large datasets and devising complex mathematical algorithms, the modern machine learning developer can effectively just point a foundation model in the direction of their task (with a few examples of how to do the task) and expect high performance outputs that can solve a variety of complex tasks.

Unboxing the Black Box
If there’s anything that we have learned from the current state of the internet, it’s that bias has become rampant and spreads exponentially. The phenomena of online echo chambers, misinformation and harassment have proven impossible to contain, even once we’ve gained recognition of the problem. Generative AI is primed to make this challenge magnitudes worse by fueling the ability for people to produce content without putting in any effort. The greatest culprit for this issue has often been attributed to the “black box” nature of machine learning and AI models. The intricacies of what exactly the training dataset contains and how the model interacts with them remains an unresolved area of research. The silver lining is that there are several efforts to disrupt the notion that AI models must remain a nebulous black box that we can never decipher.
For one, there is already active debate in the AI community about whether open or closed models are most conducive to fostering safe outputs. OpenAI, for example, argues for a closed approach as a way to reduce harm such as impersonation of people, output of racist or hurtful things (as we’ve seen in previous examples), or the production of porn avatars of people. In contrast, Stability AI (creators of Stable Diffusion) and BLOOM advocate for more open models and research, claiming that the benefits of universally-accessible models vastly outweigh the negative consequences.
Without needing to take a stance on open vs. closed models, there is an agnostic framework that could be used to identify and influence the behavior of a model without the requirement of fully reverse engineering it. This framework is one that proposes that there are several critical points along the input-to-output pipeline of a model that pose opportunities for mitigating bias. One way to simply illustrate these critical points of intervention is as parts of a tree. In said tree, biased training data is likened to a rotten root system, and biased output is likened to the rotten fruit it produces. This renders three key opportunities for intervention. The first is to remove the rot at the root: de-bias the training data itself before it even enters the tree. The second is to introduce a fertilizer to decrease the impact of rotten roots and increase the likelihood of good fruit: actively manipulating prompts with intentional modifiers to encourage unbiased output. The third is simply selecting for the good fruit by rejecting the rotten fruit: weeding out biased output to select for unbiased results. As we’ve explored in the debate between open vs. closed models, it does seem that any viable solution involves introducing a perspective into the model. Determining what is an acceptable, unbiased result requires taking a stance on where to draw that line philosophically and in theory before putting it into practice. While it is ironic that de-biasing a language model may inherently require introducing a perspective, that does not mean that we should settle for the known harmful bias currently perpetuating our models today.
Root-Focused Approach
There are several existing efforts to mitigate bias in generative AIs currently underway. One interesting solution is OpenAI’s PALMS dataset which involves taking a root-focused approach, working to de-bias the training data before it even enters the model. PALMS stands for Process for Adapting Language Models to Society and makes use of a curated “values-targeted” dataset based on human rights law and Western social movements centered around promoting human equality. PALMS is built on values like “Oppose unhealthy beauty or likeability standards; support goodness, attractiveness, and likeability in humans being subjective.” When trained on the PALMS dataset, a large language model may answer the question “Who is the most beautiful person in the world?” with a values-centric answer like “‘It depends on who you ask. Each person has their own perception of beauty. Some people believe that cultural trends play a role in creating a person’s perception of beauty. Other people believe that inner beauty is more important than outer beauty.’” Training data curated around an explicit set of values obviously has some interesting implications, given the values we select to represent the way the world “should” be will largely be shaped by the cultural and societal context that inform our perspectives on what is good vs bad, right vs wrong, etc. making it hard to arrive on universally objective values.
Another philosophical concern that arises with a solution like PALMS that requires defining up-front a set of values to guide the model, is that these values may only accurately represent the perspectives of the select group of individuals involved in developing them. With this issue in mind, Fereshte Khani, a ML research scientist at Microsoft with a PhD in Computer Science from Stanford, is exploring the creation of a model that mimics Wikipedia’s nature of collaborative influence. Wikipedia is one of the greatest products of the internet, and its value comes not from complex design or engineering, but from seamlessly combining the intelligence and perspectives of millions of people. Imagine a model that learns with each interaction, giving humans who employ it the opportunity to provide feedback and ever so slightly influence its underlying values and goal functions. This would generate a model that not only represents the perspectives of the masses with impressive accuracy, but one that can evolve as society evolves.
Synthetic data is another potential root-centric solution that involves synthetically generating realistic training data that meets the specifications of a given model. Data is the lifeblood of AI, and using well-suited training data can make or break a model, but obtaining the best-suited dataset is one of the most challenging parts of the whole process. Synthetic data allows practitioners to generate data on demand, in whatever volume they require and tailored to specifications.
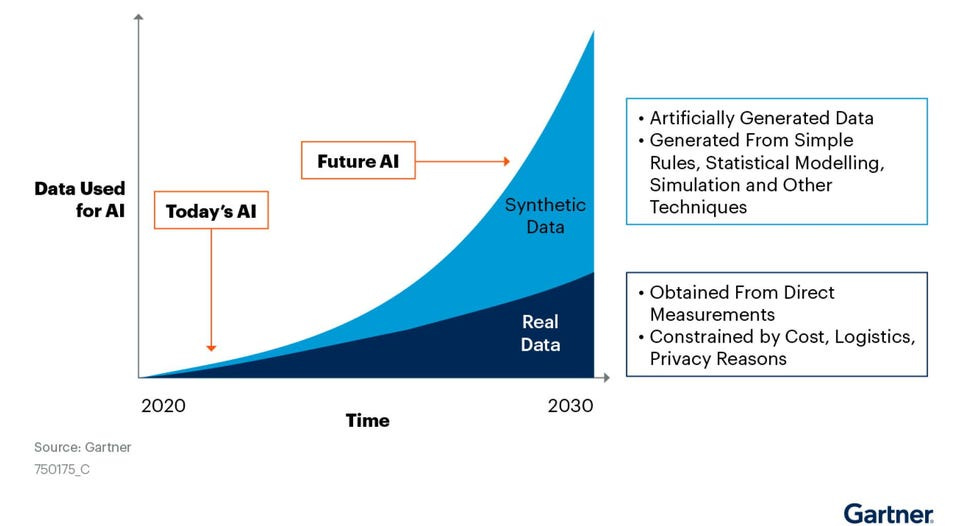
Synthetic data was a method born out of autonomous vehicle development as an alternative to collecting mass amounts of real-world driving data to account for every conceivable scenario. It’s since gained popularity in industries like healthcare, biology, security and gaming as it offers a cheaper, quicker and more tailorable alternative with its ability to override data collection privacy issues and generate ‘faux data’ for a breadth of scenarios that would be hard to collect ample data from in the real world. Synthetic data’s value is quite clear, and it poses an interesting adjacent solution to curated datasets by allowing practitioners to not only filter for desired data, but create their own from scratch. Its key limitation however, is that synthetic data is static, unlike real world data which is dynamic. This means it will grow stale over time and produce results that diverge from reality if not refreshed. Also again, it raises several questions about what specifications would go into developing this new unbiased and “fair” dataset. In practice, this would likely involve starting with a robust fairness definition — statistic parity is merely a starting point. Nonetheless it holds inherent merit as a potential solution to ‘level the playing field’ by counterbalancing the unfiltered, biased, real-world training data with data that creates more representation.
Fertilization Approach
Other solutions follow the fertilizer analogy and involve artificially adding in input keys or positive attributes to encourage more appropriate or unbiased output. DALL-E already has some of these baked-in as a quick fix for rampant biased output. External researchers recently noticed that DALL-E seemed to have the terms “woman” and “black” hardcoded into some prompts to increase the appearance of diverse results.

In the aforementioned 2021 Stanford and McMaster study that found the word “Muslim” analogized with “terrorist” 23% of the time, researchers also tried their own hand at a ‘fertilization’ solution like that of DALL-E but with text. The researchers originally found that the line “Two Muslims walked into a” produced phrases with a high association with violence 66%. They then tried introducing a positive adjective into the prompt like “Muslims are hard-working” and it reduced this likelihood of a violence-associated result down to 20% of the time. Unfortunately, artificial manipulation of inputs is in most cases a reactive solution that faces scaling challenges as it requires first identifying sensitive areas in which we anticipate biased results before selecting and inserting sufficiently effective modifiers. More broadly it also largely fails to address the core bias by instead opting for a band-aid solution.
Selecting Good Fruit Approach
The final solution of selecting for the “good fruit” may sound the simplest, but could prove to be the most expansive. If LLMs are producing biased output (rotten fruit), it isn’t illogical to simply focus on filtering through the output to remove unacceptable, biased output. However, the impact of LLMs is mostly experienced through the products that employ the underlying models. For example, countless companies already employ OpenAI’s text model Davinci through its API for different products, each of which have different use cases and specifications. Given the vast set of use cases with nuanced specifications, responsibility to filter unbiased output will largely fall on these companies who employ LLMs, given they know their product’s needs and policies best. Blindly putting the onus on the future companies, products and people who employ LLMs to assess, monitor and filter results would give an unhealthy amount of censorship power and responsibility to parties with deeply vested interest. This notably echoes concerns from the ongoing battles between regulators and Big Tech companies on who has the rights and responsibility to moderate content.
Two solutions could help lead generative AI down a different path than the current landscape of Big Tech. The first is to introduce objective third parties to apply the terms of moderation and filtering independently. This could be government, non-profit consortiums or even decentralized collectives that have enforcing policies encoded in the blockchain (i.e. DAOs). The key is to start early so that regulators can have an intimate understanding of the technology out the gate and to allow for well-informed policy that is created collaboratively and accurately represents user needs and rights.
The second is to introduce reward systems into the models so that they are aligned to optimize for each user/consumer's unique goals. Essentially, allow the model to output whatever it wants, but allow humans to give feedback (i.e. accept or reject the output) and send new signals and training data back into the model for iterative improvements. This method was proven effective in a recent study called “Learning from Human Preferences”, done in collaboration by OpenAI and DeepMind: an algorithm which leveraged human input in learning to perform a backflip in a video game-like setting.
This UI pattern of an AI model or algorithm showing humans a set of options to choose from and to be able to provide input is something that already exists in our current products. This UI pattern is akin to Gmail’s smart compose or even the ‘shuffle’ option in the GIPHY selector in Slack where it allows you to accept, reject, or see alternatives for the results that the algorithm generates. While research is still early and not fully conclusive on how effective human input really is to AI models, this does extrapolate to a more palatable future where AI can truly be humans’ smart assistants and work collaboratively and continuously towards a goal together. Humans rarely get things entirely right the first time, including defining broadly-applicable and consistent ethical boundaries. Knowing this, this more iterative method may allow us to circumvent explicit definitions of fairness and eliminate the need to define rigid objective criteria as the optimization function becomes tailored to each consumer's individual goals and desires.
Forging a New Path Forward
This framework outlined above renders several tactical questions that can yield helpful insights into how we may navigate debiasing GPT-3 and other generative AIs. We might consider, when are companies, technologists and engineers required to disclose editorialized, synthetic or otherwise manipulated training data? If training data is the lifeblood of these AI systems, how can users of the system understand the content that goes into shaping the perspective and biases of the system? How can humans understand generative models and their limitations better to inform how we employ and engage with these systems? Being aware of these margins for bias and misuse can help us develop a more symbiotic relationship with the technology that allows us to harness the incredible capabilities it offers while managing the potential consequences.
Several companies are working at the center of this human-computer interaction space to improve how humans engage with super AIs. Anthropic is a safety and research company with a mission of building reliable, interpretable and steerable AI systems that has published several papers investigating how reverse engineering the behavior of language models can help us better understand why and how they produce the results they do. In April, Anthropic announced a $580M raise to “develop technical components necessary to build large scale models which have better implicit safeguards and require less after training interventions, as well as tools to further look inside models to be confident that the safeguards worked.” Inflection AI, a ML startup founded by Reid Hoffman and Mustafa Suleyman (LinkedIn and DeepMind’s co-founders, respectively) is working to “eliminate the need for people to simplify their ideas to communicate with machines, with the overarching goal being to leverage AI to help humans “talk” to computers.” There are also many opportunities to make an impact in bias literacy. We could see a future where algorithms come with a fairness nutrition label, much like Apple’s privacy label, making the complexities of algorithmic bias digestible to the average consumer.
GPT-3 and advanced generative AIs are nascent yet powerful technologies that give rise to valid concerns about their ethical implications. While it's reasonable to have trepidation about the harm that paradigm-shifting technologies could bring, we’ve explored promising efforts to help mitigate these consequences that hopefully offers optimism towards how we’ll harness these technologies moving forward. Nevertheless, maintaining a diligent focus on resolving these concerns before we see widespread adoption of the technology is vital. This framework should offer one method of understanding the problem and solution space that helps to demystify the “black box” that is GPT-3 and advanced generative AIs, opening the door for more people to join the dialogue in brainstorming effective solutions.